Jak zničit konkurenci pomocí url
Jak zničit konkurenci pomocí „hezkých“ URL
|
Autor: Tratomik
|
21.12.2017 |
„Hezká“ URL jsou součástí většiny moderních webových aplikací. I v jejich implementaci se lze ale dopustit mnoha chyb. Jednou z nich je například reflektování URL, které protivníkovi umožní zaindexovat na Google neexistující URL adresy a tím znepřístupnit cílový web části uživatelů.
Nemalé procento aplikací, které používají „hezká“ URL, obsahují v adresách nejen název článku, nebo produktu, ale také jeho ID, pro jednoznačnou identifikaci požadovaného obsahu. Některé příklady tvaru URL, o kterém se zmiňuji, vypadají takto:
https://www.soom.cz/clanky/1184--Zranitelnosti-a-utoky-spojene-se-session-managementem
http://www.rozhlas.cz/zpravy/technika/_zprava/prvni-ultralehkou-stihacku-na-svete-sestavili-konstrukteri-z-cvut--1599713
http://www.firmy.cz/Restauracni-a-pohostinske-sluzby/kraj-olomoucky/olomouc/1048-lubenice
https://linux.slashdot.org/story/16/04/08/2138250/infographic-ubuntu-linux-is-everywhere
Samotný text, který se v adrese nachází vedle ID, je ale mnohdy ignorován, protože je použit pouze kvůli vylepšení SEO. Aplikace pro identifikaci požadovaného obsahu ovšem potřebuje znát z adresy pouze ID. Co se tedy stane, pokud tento text přepíšete svým vlastním? Aplikace se k Vašemu požadavku může postavit dvěma způsoby:
- aplikace zkontroluje, zda je uvedená hodnota textu v URL pravdivá a pokud ne, tak Vás přesměruje na adresu se správným textem
- aplikace bude změnu textu ignorovat, protože uvedený údaj k ničemu nepotřebuje a vrátí vám vyžádaný obsah na základě ID
Druhá varianta je bohužel velice častá, a proto pokládám za důležité zmínit rizika, jež s sebou toto chování přináší.
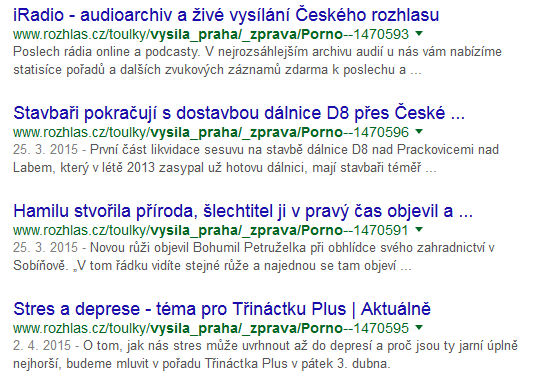
Samotné riziko se přitom neskrývají ani tak v samotné aplikaci, jako spíše v indexování obsahu například Googlem. Pokud mu totiž předložíte k zaindexování URL, které bude vypadat například takto:
pak robot, který indexuje obsah, tuto adresu navštíví, a protože je mu vrácen obsah se stavovým kódem 200 OK, a robot ještě nemá toto URL ve své databázi, tak stránku zaindexuje a přidá mezi výsledky vyhledávání. Když pak tedy bude někdo hledat například server SOOM.cz, tak mu mimo jiné vyběhne také odkaz na uvedenou stránku.
To samo o sobě ještě nemusí být problémem. Horší to bude z opačného hlediska. Představte si, že URL adresy v uvedeném tvaru používá společnost, která má na svém webu všeho všudy 10 stránek. Útočník zneužitím popsaného chování nechá na Googlu zaindexovat dalších 100 různých stránek, které budou v URL obsahovat například hanlivé výrazy. Co se pak ukáže potencionálním klientům, kteří budou tuto společnost vyhledávat na Googlu? Google jim předloží odkazy, které dokáží potencionální zákazníky webu od návštěvy spolehlivě odradit a společnost provozující web tím tak poškodí.
Mnoho firem používá při přístupu k webovým stránkám také různé filtrování obsahu, které nepustí uživatele na stránky například s hazardními hrami, pornografií, apd. Pokud potencionální klient za podobným filtrováním bude vyhledávat webové stránky poškozené společnosti, a Google mu předloží většinu výsledků obsahující výrazy, které byly injektovány útočníkem, a které neprojdou filtrem klienta, pak se potencionální klient na stránky poškozené společnosti vůbec nedostane.
Provést podobný útok přitom není vůbec složité. Stačí vytvořit webovou stránku, jejíž zdrojový kód je uveden níže a tuto stránku nechat zaindexovat Googlem na adrese https://www.google.com/webmasters/tools/submit-url. Během pár hodin bude Google zobrazovat ve svém vyhledávání všechny adresy z Vaší webové stránky.
-
<html>
-
<body>
-
<a href="http://www.rozhlas.cz/toulky/vysila_praha/_zprava/Porno--1470591">Porno</a>
-
<a href="http://www.rozhlas.cz/toulky/vysila_praha/_zprava/Porno--1470592">Porno</a>
-
<a href="http://www.rozhlas.cz/toulky/vysila_praha/_zprava/Porno--1470593">Porno</a>
-
<a href="http://www.rozhlas.cz/toulky/vysila_praha/_zprava/Porno--1470594">Porno</a>
-
<a href="http://www.rozhlas.cz/toulky/vysila_praha/_zprava/Porno--1470595">Porno</a>
-
<a href="http://www.rozhlas.cz/toulky/vysila_praha/_zprava/Porno--1470596">Porno</a>
-
…
-
</body>
-
</html>
Subdomény a DNS
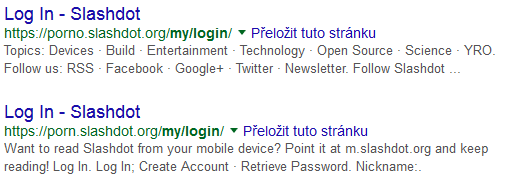
Stejná rizika s sebou přináší také subdomény, neboť některé weby mají v DNS uvedeny tyto záznamy:
*.example.cz CNAME example.cz
Pokud taková aplikace sama nekontroluje hodnotu subdomény, je stejným způsobem možné injektovat do výsledků vyhledávání Google také nejrůznější výrazy obsažené v subdoménách, například:
sex.example.cz
hazard.example.cz
…
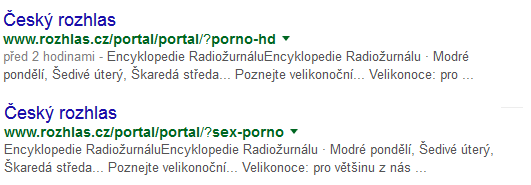
GET proměnné
Bohužel hezká URL a subdomény nejsou jedinými možnostmi, kterými je možné přinutit vyhledávací roboty zaindexovat neexistující URL. K zaindexování nakažených odkazů lze zneužít také názvy a hodnoty smyšlených GET proměnných, viz. nakažené výsledky z Google search z následujícího obrázku.
Obrana proti tomuto typu útoku je již poněkud paranoidní. Pokud bychom se ale chtěli vyhnout i tomuto typu zneužití, bylo by nutné kontrolovat, zda URL neobsahuje jiné než povolené parametry a jejich hodnoty. Názvům a obsahu jednotlivých proměnných naštěstí Google nepřikládá při vyhedávání téměř žádnou váhu.
Obrana
Pokud používáte výše popsaná „hezká“ URL obsahující ID požadovaného obsahu, neměla by vám být lhostejná hodnota řetězce, která není pro samotnou činnost aplikace důležitá. Vždy byste měli zkontrolovat, zda tato hodnota odpovídá očekávané hodnotě pro konkrétní ID a v případě, že je odlišná, měli byste provést přesměrování na správnou adresu.
Na druhou stranu lze uvedeného chování využít i ve svůj vlastní prospěch, kdy jeden článek můžete zaregistrovat pod více různými URL, kterým vyhledávače přikládají největší váhu. Počítat ale musíte s tím, že se Vám pak bude pagerank tříštit mezi všechny tyto stránky.
To samé platí i pro subdomény, pokud máte v DNS záznam s aliasem pro libovolné hodnoty. Aplikace by v případě obdržení požadavku na nedefinovanou subdoménu měla provést přesměrování na konkrétní doménu třetího řádu, například „www“.